[Deep Learning]将逻辑回归模型作为神经网络
最近开始学习吴恩达的deeplearning课程,从第二周开始,会开始介绍关于逻辑回归模型的一些简单定义,在这里开始做一些简单的笔记,用以后面的复习。
也就是说
如果 y=1
如果 y=0
将两种情况写在一起 即为 (将y=0 y=1 代入 可以得到与上面相同的公式)
又由于log函数为单调增函数,故取对数
注意这里的负号,因为在逻辑回归中,我们想最大化概率,所以就需要最小化损失函数。
代价函数(COST)
在m个样本中的代价可以定义为
(在统计学中,有一种最大似然估计的方法,即选择使式子最大化的参数。)
则有
因为这里要求最小值,故不需要这个负号(1/m 为缩放系数,只是为了最后的数值能在更好的尺度上,没有其他特殊含义)
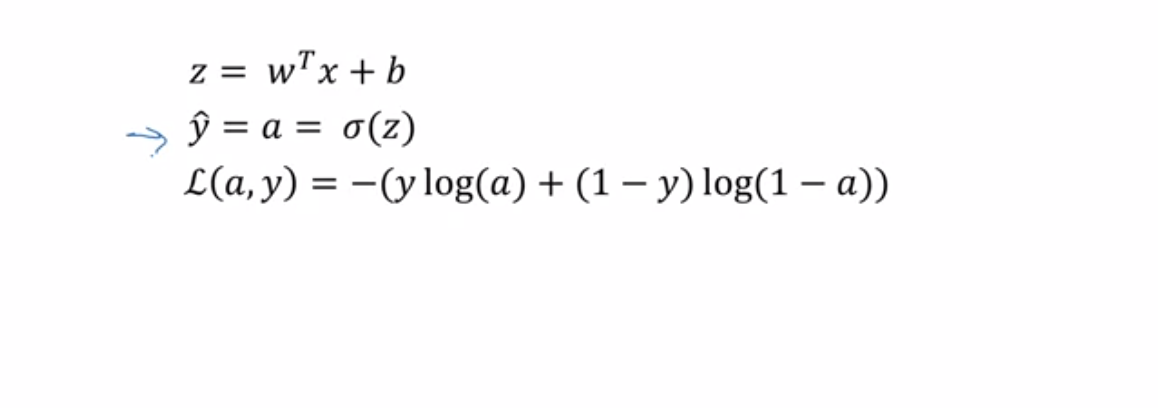
注:
则有
同样的
在计算出这些导数后,就可以进行梯度下降了
以上就是对第二周的小小整理(没有对向量化的部分以及numpy的使用做总结,关于numpy的使用会单独写),具体来说,这门课和之前的机器学习中讲的略有不同,比如记号之类的地方,但是大体而言还是差不多的,加油加油!

