[Deep Learning] 浅层神经网络
- 理解隐藏层和隐藏单元
- 能够使用多种类型的激活函数
- 用隐藏层建立一个前向传播和反向传播算法
- 应用随机初始化
浅层神经网络结构
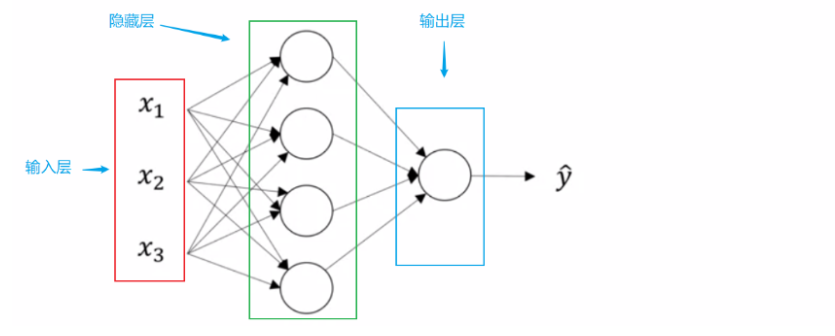
这是一个两层的神经网络(输入层不算做一层,认为是第0层)。一般用 X 代表输入,也可以用 表示 (a代 表激活的意思),用代表第一层即隐藏层,代表输出层。所以上图中 ,X = ,, 。 现在来看隐藏层第一个节点即的计算,这个计算和逻辑回归一样。首先算出
然后计算
其他节点 同理计算,整理一下
第一个矩阵为4 x 3的矩阵 ,这是因为都属于 三维列向量,现在将他们的转置竖直拼 接为新的矩阵,所以维度4x3。简化一下,可以得到下面的公式
因为 x 可以写作,所以
其中,,所以最后 也是一个实数。
到此,就完成了一个实例的神经网络计算。
接下来 讨论一下对于多个样本的计算:
首先解释一下符号的意思, 第i个样本第k层的节点定义为。
则在计算m个样本的时候,需要像下面这样计算
for i = 1 to m:
则 向量化 如下
同样的 , ,都是矩阵。到此就已经全部完成了。
激活函数
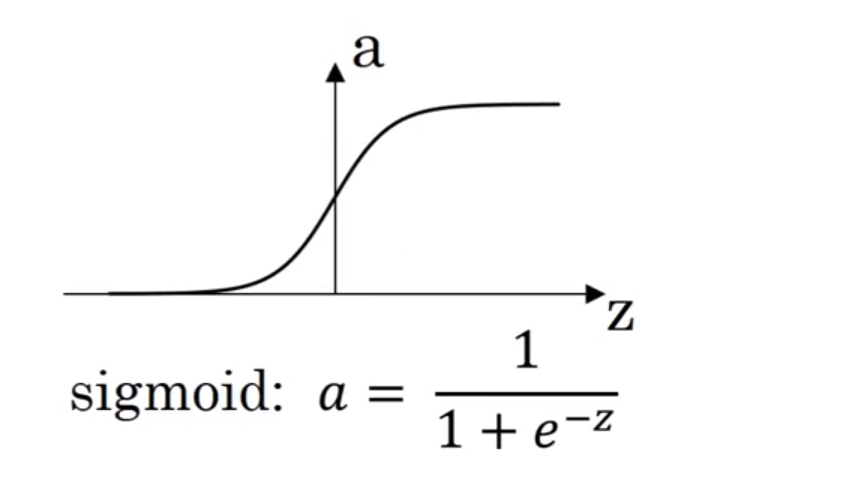
可以看到,当z非常大或者非常小的时候,它斜率也非常小,这样会使梯度下降很慢。所以基本上不会使用这个激活函数。 除非在做二元分类的时候,需要输出值在o-1之间,只有在这个时候会在输出层选择它。需要注意的是,对于隐藏层和输出层来讲,可以选择不同的激活函数。
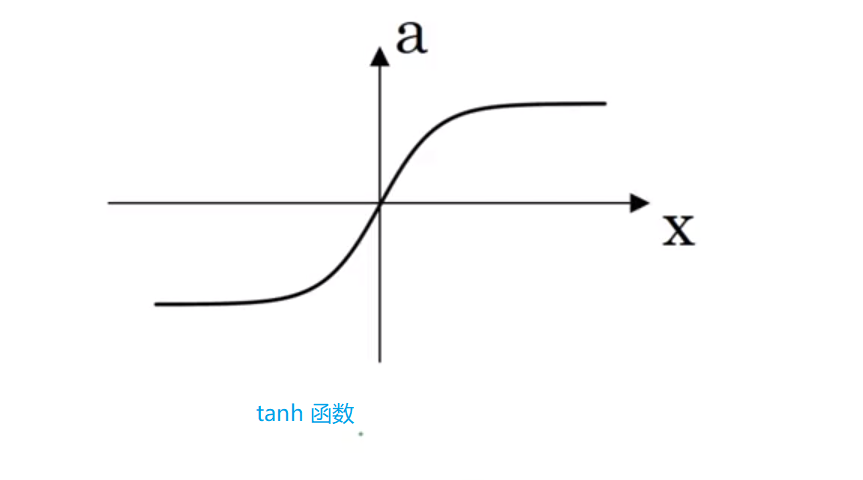
其实是sigmoid函数经过变换后得来的。尽管他的表现要比sigmoid函数要好,但是仍旧面临同样的问题,就是当z过大或过小的时候,斜率非常小。所以也不怎么使用它。
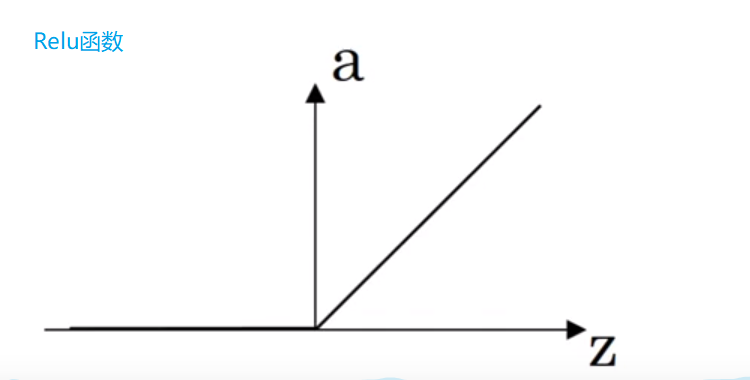
所以只要z为正数,那么斜率就一直为1,z为负数时,斜率为0。虽然当z=0时,导数无定义(左导数和右导数不相等),但是在实际编程时,遇到z=0的概率非常非常小,并且也可以通过指定z=0时,导数为0或者1,所以不用纠结这个问题。
所以一般情况下都用ReLU,或者在你不知道使用哪种激活函数时,就选择它。就比如我们在做二元分类的问题时,可以将所有隐藏层的激活函数都设置为ReLU,然后将输出层的激活函数设置为sigmoid。
此外 ,ReLU函数还有另一种版本。
它的公式为 ReLU = max(0.01z,z) , 图像长这样:
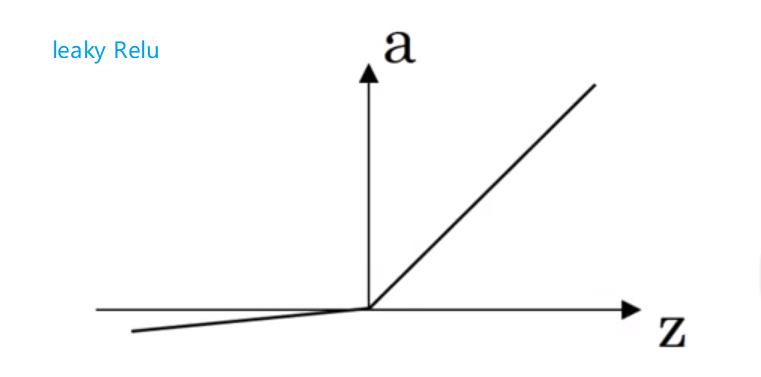
当z为负数时,它的斜率不在为0,而是一个轻微的倾斜。这种激活函数实际上使用起来和ReLU没什么太大的区别,具体可以看个人爱好,或者在你的模型中,将两种都尝试一下,来试试效果。
顺带说一句,因为在NN中,有足够多的隐藏单元来使得z为正数,所以在使用ReLU的时候也不用太担心梯度下降的问题。
激活函数求导
sigmoid
关于它的求导,可以参考上一篇博客:neural-networks-deep-learning-week2
这里就不再赘述。
tanh 函数
首先,有它的公式
则有
具体求导过程可以自行求导,不是很难
神经网络中的梯度下降
现在需要讨论 在NN 中如何进行梯度下降,假设目前还是做得二元分类问题且只包含一层隐藏层,那么我们有损失函数的定义如下:
- 梯度下降的做法就是用 变量 减去 学习率与对应偏导数的乘积
整个过程就是这样,如果不是很明白,可以去B站搜一搜,有很多推导过程,由于时间所限,这里就不一一推导。
随机初始化
在逻辑回归中,将权重参数全部初始化为0这是可以的,但是在NN中这是不行的。我们来看一看这是为什么。
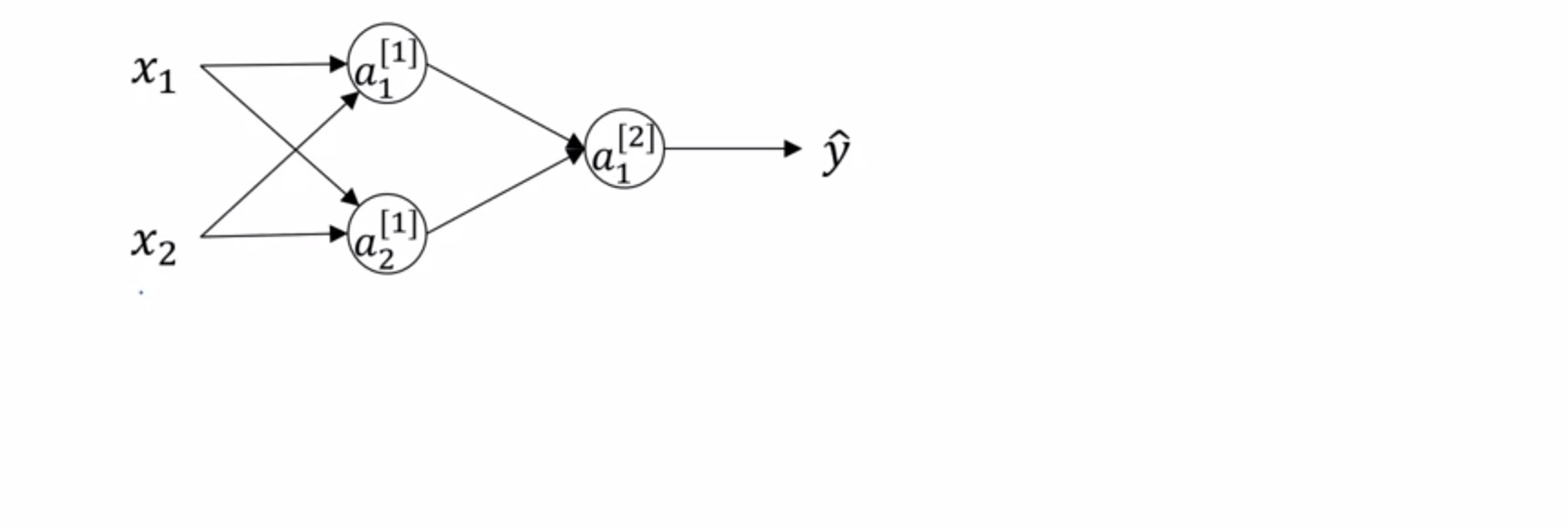
在上图中,有两个输入即, 隐藏层有两个单元即,那么是一个2x2的矩阵,是一个2x1的矩阵。而这会导致无论输入是什么,总有。当进行反向传播的时候,由于对称问题,会导致 =
……
因此,如果全部初始化为0的话,所以的隐藏单元实际上都是相同的,无论训练多久,它们始终相同。推广到多个隐藏层,隐藏单元也依旧成立。所以需要随机初始化。
本周内容相对而言稍微难一点,主要是反向传播中的链式求导,不太熟的可以去看看链式求导法则。最好是要搞懂原理,不然在之后的多层网络中会比较难以理解

